

- 5.17 MB
- 52页


- 1、本文档共5页,可阅读全部内容。
- 2、本文档由网友投稿或网络整理,如有侵权请及时联系我们处理。
'核电厂热工水力学6
1流动沸腾传热流动沸腾是指液体有宏观运动的系统内的沸腾,加热面上汽泡生长受到液体流动方向上的附加作用,使壁面的泡化过程特性发生变化。液体运动可以是由外力强制作用引起的强迫流动,也可以是由流体密度差造成的自然对流。流动沸腾常伴随着各种汽—液两相运动,所以它比池内沸腾复杂。
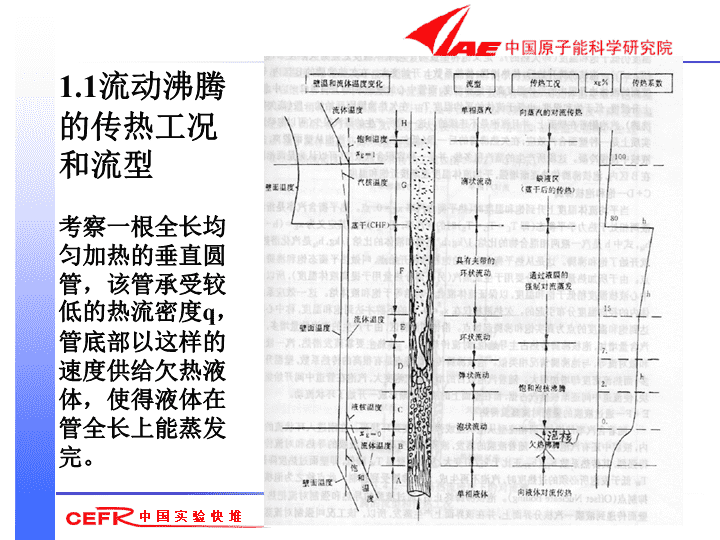
1.1流动沸腾的传热工况和流型考察一根全长均匀加热的垂直圆管,该管承受较低的热流密度q,管底部以这样的速度供给欠热液体,使得液体在管全长上能蒸发完。
1.3常用的泡核沸腾(包括欠热和饱和泡核沸腾)传热关系式
1.4泡核沸腾起始点(ONB)的确定,汽泡开始脱离壁面点(FDB)的确定,热平衡态饱和沸腾起始点的确定在热流密度沿管均匀分布加热情况下,A、B、C三区的传热工况、流体平均温度和壁面温度沿流动方向的变化。由于流体压力沿管长稍减小,所以饱和温度亦沿管长稍下降
1.4.1泡核沸腾起始点(ONB)的确定
1.4.2汽泡开始脱离壁面点(FDB)的确定在该点之前,由于主流液体的温度很低(即高欠热度),当汽泡顶端一进入欠热液体便立即凝结。因此,汽泡只能在很薄的过热边界层内黏附在壁面上。随着主流液体温度和壁面温度的升高,汽化核心数目增多,汽泡长大并开始脱离壁面,泡核沸腾传热增强(占主导地位),所以,汽泡开始脱离壁面点也可以看作充分发展的欠热泡核沸腾开始点(FDB)。由于汽泡脱离开壁面,使蒸汽含量表现出一种容积效应,所以,该点也叫净蒸汽产生开始点。在该点之后,可以认为是汽—液两相流动。
1.4.3热平衡态饱和沸腾起始点的确定
1.5两相强制对流蒸发传热(E+F)关系式
1.6流动沸腾临界热流密度(CHF)临界热流密度工况是指传热机理正好发生变化而使传热系数突然下降(即传热恶化)的状态,临界热流密度(CHF)则指在该工况下的热流密度的数值。有两种CHF工况:偏离泡核沸腾(DNB型)在高热流密度下,沸腾可以由欠热泡核沸腾或低含汽率的饱和泡核沸腾直接进入膜态沸腾(欠热或饱和膜态沸腾),这种由泡核沸腾直接向膜态沸腾的转变叫偏离泡核沸腾(DeparturefromNucleateBoiling)。它可以分欠热的DNB和饱和的DNB。DNB机理的特点是在壁面上形成蒸汽膜覆盖壁面,使液体不能接触壁面,从而使传热恶化,造成壁温急剧升高。一般说来,DNB发生时壁温跃升是如此之高,以至于可能使壁面立刻烧毁。
干涸或蒸干(Dryout)在低热流密度和高含汽率的环状流动区,附壁液膜会因蒸干或撕破等原因而消失,从而导致壁面干涸。干涸发生时,由于蒸汽流速较高,其传热能力并不太低,因而壁温上升不很剧烈,一般不会使壁面立刻烧毁。
1.6.1棒束通道的临界热流密度(CHF)关系式
A单通道CHF关系式推广用于棒束
B由棒束临界热流密度实验数据整理的CHF关系式
1.6.2影响临界热流密度的主要参量和因素
1.7蒸干后的传热(PostDryout)
第四节抽样分布总体分布:总体内个体数值的频数分布。样本分布:样本内个体数值的频数分布。抽样分布:某一种统计量的频数分布。抽样分布是一种理论的概率分布,是统计推断的理论依据。志存高远,顽强拼搏
总体分布:所有元素出现概率的分布。是简单意义上的随机变量对应的频次分布。总体分布往往是未知的,很多场合不可能获取得对所有个体元素的观察值。当然有些时候可以通过理论计算进行假定。样本分布:选择的样本在随机变量上的对应的频次分布,样本分布实际上也在趋向总体分布。样本分布和总体分布的本质是一样,区别就在于选取的数据不一样,一个是总体(N个),一个是样本(n个)抽样分布是对样本统计量概率分布的一种描述方式。这个和上面两个是截然不同的概念。虽然统计量也是随机变量,但是本身来说,是经过处理的变量。在使用时需要计算任意n个样本的统计量,然后将数据进行分布查看。由样本n个观察值计算的统计量的概率分布就是抽样分布。抽样分布有什么特征,抽样分布是什么样的分布,这要根据总体是否正态、总体方差是否已知、样本统计量是什么等因素确定。
一、正态分布与渐进正态分布(一)如果总体呈正态分布,且总体方差已知,那么,样本平均数的抽样分布为正态分布。此时,样本平均数的平均数等于总体平均数,样本平均数在抽样分布上的标准差,等于总体标准差除以N的平方根。志存高远,顽强拼搏
(二)如果总体不呈正态分布,但2已知,且样本容量较大,此时,样本平均数的抽样分布接近正态分布。上述两种情况,都可以将样本平均数转化成标准分数:志存高远,顽强拼搏
(三)如果总体呈正态分布,总体方差未知,样本是大样本,那么,样本平均数的抽样分布为渐进正态分布。(四)依随机取样的原则,自正态分布的总体中抽取容量为n的样本,当n足够大时(n≥30),样本方差及标准差的分布,渐趋于正态分布。志存高远,顽强拼搏
二、t分布当总体为正态分布,但总体方差未知,而且N<30时,样本平均数的分布为t分布。(一)什么是t分布若干个来自已知平均数为U,而方差未知的正态分布总体的样本统计量的分布。t分布是统计分析中应用较多的一种随机变量函数的分布,是统计学者高赛特(Goeset)1908年在以笔名"Student"发表的一篇论文中推导的一种分布。志存高远,顽强拼搏
(二)t分布的特征1.t分布的平均值为0。2.t分布是以过平均值0的垂线为轴的对称分布,分布左侧t为负值,分布右侧t为正值。3.t变量取值在--∞—+∞之间。4.当样本容量趋于+∞时,t分布为正态分布。5.t分布的形态随自由度的变化而变化,呈一簇分布形态(即自由度不同的t分布形态也不同);t分布的峰狭窄尖峭,尾长而翘得高。志存高远,顽强拼搏
t分布与标准正态分布的比较相同点:1.以过平均数的直线为轴,两侧对称;2.曲线在平均数这一点上有最高点;3.曲线从中央点向两侧逐渐下降,但永远不与基线相交;4.曲线下的面积为1,以平均数为界,左右各占0.5。不同点:t分布随自由度的变化,是一簇分布;标准正态分布不随自由度的变化而变化。联系:当自由度趋于无穷大时,t分布接近标准正态分布。志存高远,顽强拼搏
(三)自由度指总体参数估计量中变量值自由变化的个数,用符号df表示。任何变量中可以自由变化的数目。自由度(degreeoffreedom,df)在数学中能够自由取值的变量个数,如有3个变量x、y、z,但x+y+z=18,因此其自由度等于2。在统计学中,自由度指的是计算某一统计量时,取值不受限制的变量个数。通常df=n-k。其中n为样本含量,k为被限制的条件数或变量个数,或计算某一统计量时用到其它独立统计量的个数。自由度通常用于抽样分布中。志存高远,顽强拼搏
统计学上的自由度是指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的自变量的个数,称为该统计量的自由度。统计学上的自由度包括两方面的内容:首先,在估计总体的平均数时,由于样本中的n个数都是相互独立的,从其中抽出任何一个数都不影响其他数据,所以其自由度为n。在估计总体的方差时,使用的是离差平方和。只要n-1个数的离差平方和确定了,方差也就确定了;因为在均值确定后,如果知道了其中n-1个数的值,第n个数的值也就确定了。这里,均值就相当于一个限制条件,由于加了这个限制条件,估计总体方差的自由度为n-1。例如,有一个有4个数据(n=4)的样本,其平均值m等于5,即受到m=5的条件限制,在自由确定4、2、5三个数据后,第四个数据只能是9,否则m≠5。因而这里的自由度υ=n-1=4-1=3。推而广之,任何统计量的自由度υ=n-限制条件的个数志存高远,顽强拼搏
(四)t分布表的使用左列表示自由度。最上一行表示不同自由度下t分布两端的概率之和,即在某t值时,t分布两端的概率之和,又称显著性水平。中间数字:某一自由度和某一显著性水平t的临界值。志存高远,顽强拼搏
不管是正态分布,还是在t分布,都存在标准误问题.标准误的含义:某种统计量在抽样分布上的标准差,符号SE表示。包括:样本平均数的标准误;样本标准差的标准误;样本相关系数的标准误;标准差与标准误的异同:都是描述数据的离中趋势,即都是离中趋势的指标标准差是一般变量值离中趋势的指标标准误是样本统计量离中趋势的指标抽样误差:从总体中抽取容量为的个样本时,样本统计量与总体参数之间总会存在一定的差距,而这种差距是由于抽样的随机性所引起的样本统计量与总体参数之间的不同,称为抽样误差。志存高远,顽强拼搏
三、χ2(卡方)分布(一)χ2(卡方)分布的含义从一个服从正态分布的总体中,每次随机抽取随机变量X1,X2,X3…XN,并分别将其平方,即可得到X12,X22,X32…,XN2,这样可抽取无限多个数量为n的随机变量X,并可求得无限多个n个随机变量X的平方的和,也可计算其标准分数Z=X-μ/δ,及其平方Z2=(X-μ/δ)2。这无限多个n个随机变量平方和或标准分数的平方和的分布,即为χ2分布。χ2分布是统计分析中应用较多的一种抽样分布。志存高远,顽强拼搏
(二)χ2分布的特点1、是一个正偏态分布。随每次所抽取的随机变量X个数(n的大小)不同,其分布曲线的形状不同,n或n-1越小分布越偏斜,df很大时,接近正态分布。当df→∞时,χ2分布为正态分布。可见χ2分布是一族分布,正态分布是其中一特例。2.卡方值都是正值。3.卡方分布的和也是卡方分布。4.χ2分布是连续型分布,但有些离散型的分布也近似χ2分布。志存高远,顽强拼搏
(三)χ2分布表的编制与使用χ2分布表是根据χ2分布函数计算出来的,χ2分布曲线下的面积都是1。但随自由度不同,同一χ2值以下或以上所含面积与总面积之比率不同。故一般χ2表,要列出自由度、及某一χ2值以上χ2分布曲线下的概率。志存高远,顽强拼搏
四、F分布(一)F分布的含义自一个正态总体中随机抽取容量为n1及n2两个样本,它们的总体方差估计值的比值F的分布称为F分布(分子的自由度为n1-1,分母的自由度为n2-1)。知道了同一总体不同样本的总体方差估计值F的分布,即可分析任意两样本方差是否取自同一总体了。可见,F分布在统计分析中是很有用的一种样本分布。志存高远,顽强拼搏
(二)F分布的特点1.F分布形态是一个正偏态的分布,它的分布曲线的形式随分子、分母的自由度不同而不同,它是一族分布,随df1与df2的增加而渐趋正态分布。2.因F为两个方差之比率,故F总为正值。3.F分布表是根据F分布函数计算得来。4.当分子的自由度为1,分母的自由度为任意值时,F值与分母自由度相同概率的t值(双侧概率)的平方相等。志存高远,顽强拼搏
(三)F分布表的使用该表左一列为分母的自由度从1-30比较详细,30以后只列出间隔较大的一部分自由度。表的左二列为α概率:0.05与0.01即F曲线下某F值之右侧的概率,表的最上行为分子的自由度,其值与分母自由度的值相似。表中其他各行各列的数值为0.05与0.01概率时,不同分子、分母自由度时F分布的值。志存高远,顽强拼搏
抽样分布:某一种统计量的频数分布。(一)当总体为正态分布,总体方差已知时,样本平均数的分布为正态分布。此时,样本平均数的平均数等于总体的平均数;样本平均数的标准差,等于总体标准差除以N的平方根。当总体为正态分布,总体方差未知,且样本为大样本时,样本平均数的分布为渐近正态分布。当总体为正态分布,样本为大样本时,样本方差及标准差的分布为渐近正态分布。(二)当总体为正态分布,但总体方差未知,且N<30时,样本平均数的分布为t分布。此时,样本平均数的平均数等于总体平均数;样本平均数的标准差,等于样本标准差除以N-1的平方根。
(三)无限多个n个随机变量平方和或标准分数的平方和的分布,称为χ2分布。χ2分布是正偏态分布;卡方值都是正值;卡方分布的和也是卡方分布;χ2分布是连续型分布。(四)自一个正态总体中随机抽取容量为n1及n2两个样本,它们的总体方差估计值的比值F的分布称为F分布。'
您可能关注的文档
- 水力学画图与计算复习课程.doc
- 大学课件-水力学题库-第六章恒定管流.doc
- 水力学课程总结-(2).ppt
- 草坪灌溉与排水工程学第四章-管道水力学原理.ppt
- 大学课件-水力学题库-第七章明槽恒定流动.doc
- 《水力学》本科网上作业题20130709新.doc
- 水力学与水泵复习题(含答案).doc
- 最新[工学]四川大学水力学第二章液体运动的流束理论教学讲义ppt.ppt
- 最新核电厂热工水力学6课件PPT.ppt
- 水力学复习资料.docx
- 武大水力学习题第2章 水静力学.docx
- 硕士研究生入学考试《水力学》考试大纲.docx
- 最新水力学课后习题详解教学讲义ppt.ppt
- 水力学(B)网考复习资料.doc
- 第二章排水管渠水力学计算.ppt
- 水力学题教学文案.doc
- 《水力学作业答案》word版.doc
- 工程流体水力学第六章习题答案.docx